✔ Problem with HTML excerpts in Full Text Search Results
Completed by Morgan M.
- Assigned to
-
 Harsh P.
Harsh P.
 Radomir M.
Radomir M.
- Notes
-
Further to the video below, within the Full Text Search the excerpts generated from HTML documents are not including the formatting required to present quotation marks and other symbols (e.g., ¶). Could you please ensure these excerpts have similar formatting to the other research tools.
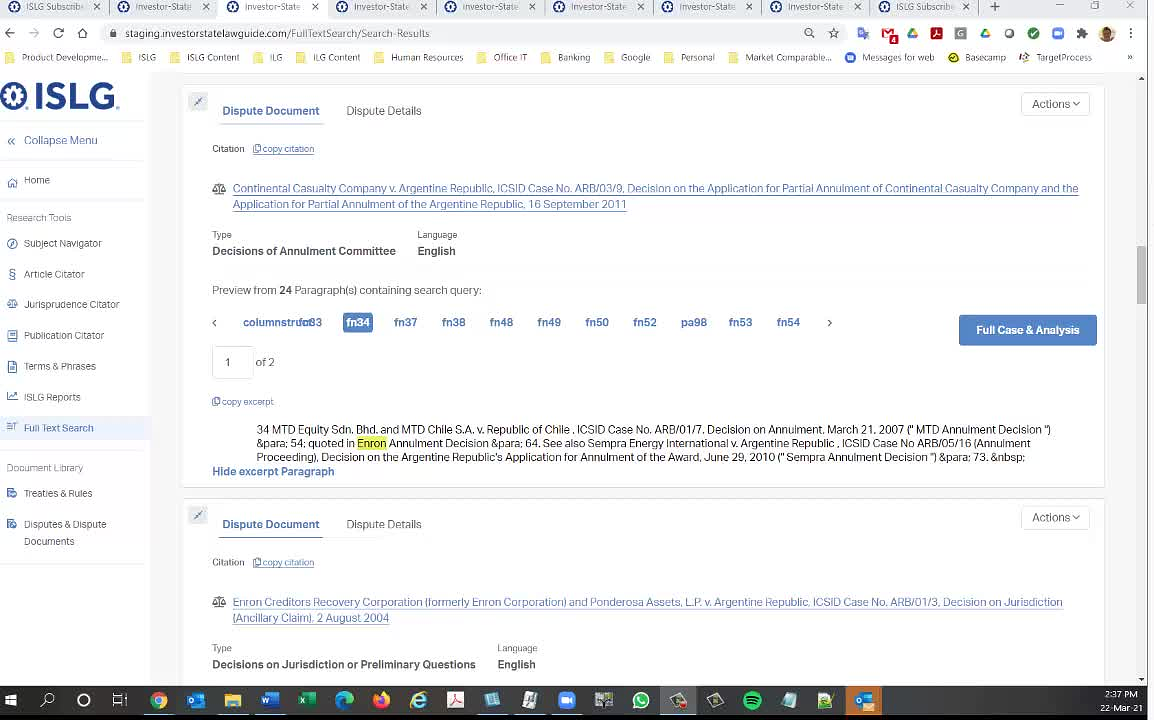
This html or PDF text handled by DTSeacrh so we haven't any control on that. the dtsearch have to provided the formatted text.
Thanks,
Morgan
I guess you're adding the paragraph to the page as text instead of raw html.
As discussed in today's call, The JSON request from dtsearch provide us unicode text. so, please look into this and provide feedback.
Here, I have attached sample html where we get Unicode latter while click on paragraph number.
After updating the FTS Indexes, the html excerpt Unicode issue is resolved.
But, when I pass the following Search request to get text then it is doesn't fetch the text from PDF (Page 4)
{"searchRequest":"tribunal","SearchType":"3","Stemming":"false","WordNetSynonyms":"false","Fuzzy":"false","Fuzziness":"1","paraId":"EE073142D5FC08C5509D1A05E23D7D27#NA=="}
But in Same Document if I pass this search request to get text then it display text. (Page 8)
{"searchRequest":"tribunal","SearchType":"3","Stemming":"false","WordNetSynonyms":"false","Fuzzy":"false","Fuzziness":"1","paraId":"EE073142D5FC08C5509D1A05E23D7D27#OA=="}
Here, I have attached PDF File. The text is fetching from this PDF file. In old indexing it was works for above both search request.
This issue is resolved on staging.islg. Please check and confirm.
Thanks,
Morgan
The above change has been done on staging.islg. Please check and confirm.
Note the issue I experienced with the searches in the Subject Navigator, FTS and Dispute Documents noted here: Re: 2021-03-25 08.19.13 Weekly Tologix-DevIT-Industrial Meeting 81175607260.mp4 - TOLOGIX - ISLG App Rebuild. However, I will assume this is just a indexing issue for the time being, and will mark this to-do complete.
Thanks,
Morgan